


 Поделиться
Поделиться
Облака в облаках: ИТ-инфраструктура платформы Учи.ру
В конце 2019 г. количество детей, занимающихся на образовательной онлайн-платформе Учи.ру, превысило 3 250 000 человек. Об облачной инфраструктуре компании, ее особенностях, изменениях и вызовах для DevOps рассказывает Валерий Браткевич, старший системный инженер Учи.ру.
Особенности деятельности компании
Компания Учи.ру — одна из крупнейших в стране образовательных онлайн-платформ для школьного образования. Мы производим обучающий контент для детей с 1 по 11 класс по математике, английскому и русскому языку и другим предметам.
На данный момент более 3 млн детей из России, Бразилии, США, Канады, Китая, ЮАР и других стран решают задания интерактивных курсов и олимпиад. Более 300 000 учителей используют платформу в уроках и для дополнительных заданий. Ежедневно в течение учебного года на платформу заходит около полумиллиона пользователей. Кроме курсов на основном сайте мы делаем олимпиады на отдельных платформах. Олимпиады запускаются каждые 2 недели и длятся в среднем около месяца.
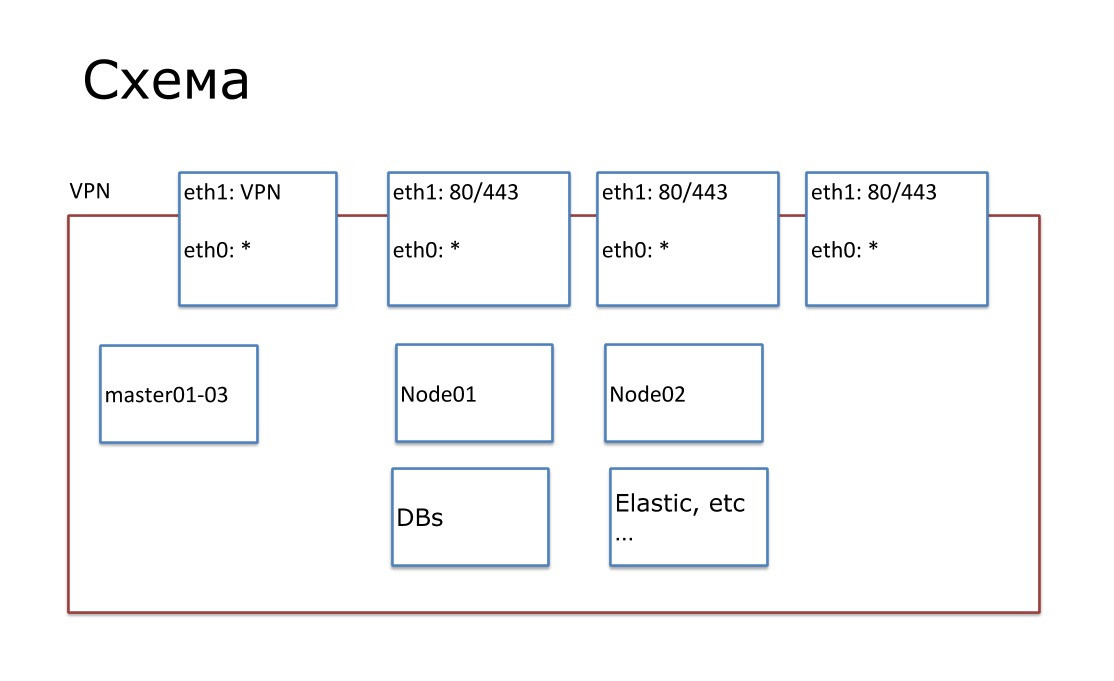
Специфика ИТ-модели инфраструктуры
Сегодня команда ИТ в компании разделена на несколько направлений: DevOps, специалисты по машинному обучению, недавно отделившаяся команда BI, а также распределенные по продуктовым командам разработчики и тестировщики. Всего более 140 ИТ-специалистов, в инфраструктурной команде — 5 человек.
Наша инфраструктура представляет собой классический облачный стек технологий. Состоит из изолированных независимых проектов с API на разных virtual private cloud. Такая схема инфраструктуры очень удобна — например, нарушение работы на одной площадке не повлияет на остальные.
Производительность облачной инфраструктуры на данный момент:
- более 400 серверов;
- более 1000 ядер CPU;
- более 4 ТБ оперативной памяти;
- более 300 приложений/сервисов в поддержке.
Все наши проекты хостятся полностью в публичных облаках. Для нас это оптимальный вариант, в отличие от, например, выделенных серверов. В публичных облаках можно быстро автоматически развернуть и свернуть проекты, что очень важно для нашей динамичной внутренней среды. К примеру, трафик на платформы олимпиад в первые дни после запуска очень большой, но через неделю стабилизируется. Подготовить запас ресурсов под начало олимпиады нам помогает нагрузочное тестирование — оно помогает нам определить количество серверов, которые необходимо добавить к текущему объему. Одновременно с этим мы создаем новые проекты, что-то тестируем и сворачиваем.
На сегодняшний день у нас 13 продуктовых площадок, которыми мы управляем с помощью 14-й мастер-площадкой, доступ к которой есть только у инфраструктурной команды. Для сборки, отладки и развертывания приложений мы используем технологию Docker, в качестве оркестратора Docker-кластеров — утилиту Nomad.
Выбор облачных провайдеров
Выбор облачного провайдера, как правило, зависит от требований к хранению персональных данных в стране. Так, в России мы используем облака Selectel, в США — Google Cloud Platform, в Бразилии — Microsoft Azure, в Индии и Южной Африке — Amazon Web Services, в Китае — Alibaba Cloud.
Также при выборе провайдера мы учитываем стабильность и удобство в использовании, возможность управления через API провайдера, возможность быстро масштабироваться, хранить все настройки и шаблоны в виде кода. Обычно для нас оптимальны условия таких провайдеров, как Google Cloud Platform или Amazon Web Services, но если в каком-то регионе они не представлены, мы рассматриваем местных провайдеров или хостим проект на серверах в других странах. Так, например, произошло в случае с Южной Африкой, хотя сначала мы работали с местным провайдером.

Управление инфраструктурой
Вся инфраструктура как код хранится в системе контроля версий Git в одном репозитарии. Для управления инфраструктурой как кодом мы используем набор инструментов.
Настройку серверов выполняем с помощью системы управления конфигурациями Ansible. Для управления ресурсами инфраструктуры в виде кода используем Terraform. Все наши площадки разделены по папкам и в каждой папке ресурсная часть (например, сервера) описана в виде Terraform-кода, а конфигурация — в виде Ansible-кода.
Все приложения мы запускаем в Docker. Для этого используем стек HashiCorp: Nomad и Consul. С помощью Consul мы делаем health-check, service discovery и key/value. Nomad отвечает за шедулинг, выкатки и распределенный cron.
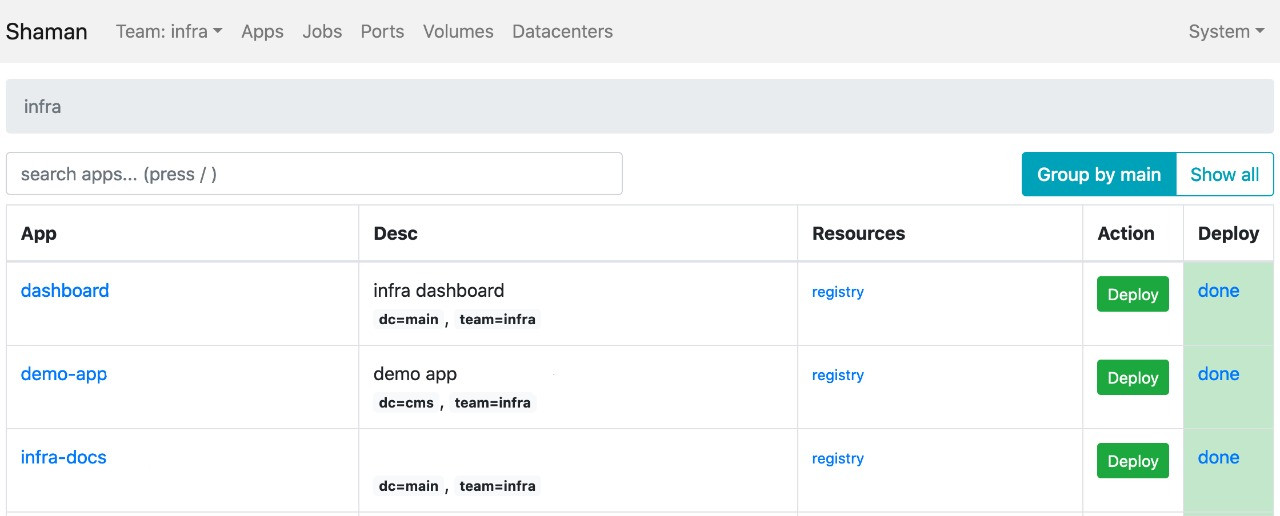
Развертывание программного обеспечения осуществляется с помощью внутреннего самописного инструмента Shaman, который разработчики используют самостоятельно как веб-интерфейс к Nomad. Через него можно видеть список приложений и менять конфигурации: добавлять контейнеры, переменные среды, заводить сервисы.
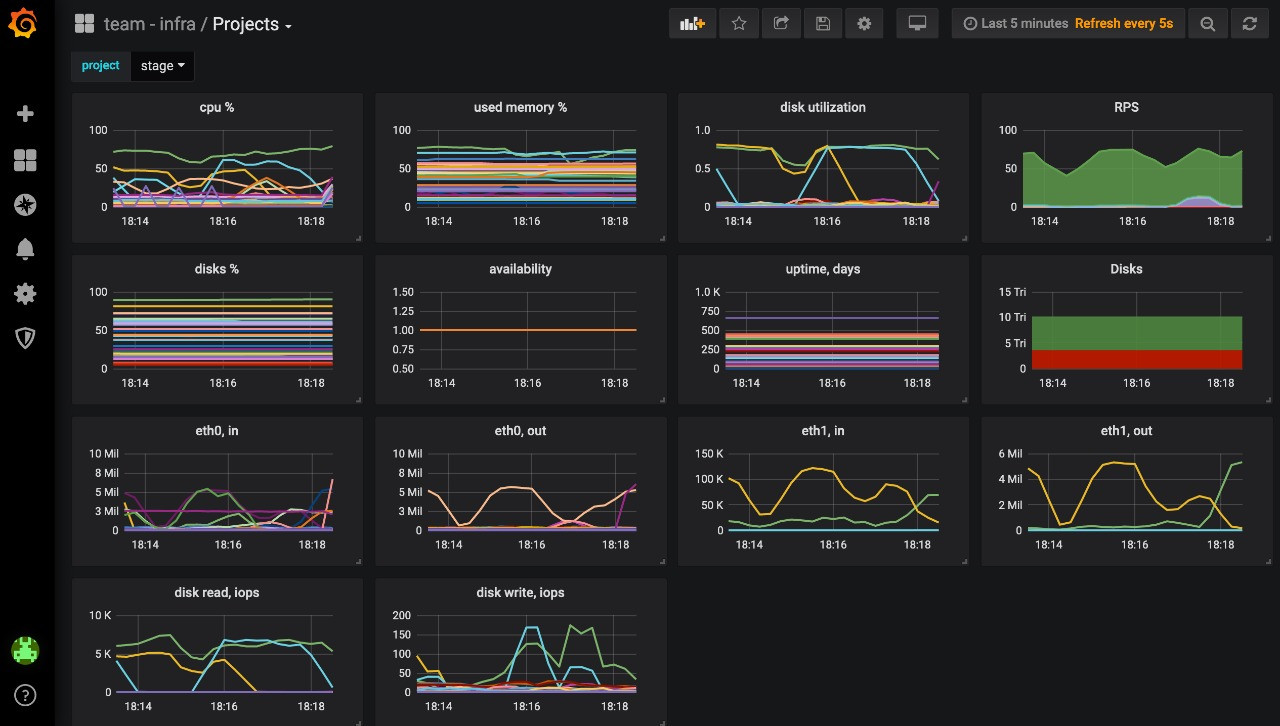
Для мониторинга всей инфраструктуры мы используем Prometheus, для алертинга — Alertmanager. Prometheus собирает метрики со всех площадок по модели федерации в мастер-Prometheus, который находится на площадке, доступной только инфраструктурной команде.
Все графики мы выводим через Grafana — продуктовые команды могут самостоятельно следить за состоянием приложений. В качестве дополнительного мониторинга используем New Relic Saas, который позволяет искать узкие места в работе приложения. Для отдельного сбора и обработки ошибок приложений мы используем Honeybadger.
Изменения и улучшения
За последние 2 года мы несколько раз меняли подходы во взаимодействии с инфраструктурой. Например, Prometheus и Grafana сначала использовали на каждой отдельной площадке, затем уперлись в сложность сопровождения и создали мастер-Prometheus и мастер-Grafana, через которые со всех площадок собираем метрики в одном месте. Так мы управляем графиками и следим за всей инфраструктурой из одной точки.
Для генерации SSL сертификатов мы используем Let's Encrypt. Генерацию сертификатов для части сабдоменов мы делали скриптами или вручную. Позже оформили все как часть нашего CLI (внутренний инструмент для шаблонизации площадок) и теперь у нас есть только команда с выбором поддомена, на который генерируется сертификат и все раскладывается по балансировщикам нагрузки.
Для централизованного сбора логов мы использовали rsync. Когда-то логи с приложений собирались в файлы на сервере, где их можно было просматривать. Сейчас мы собираем логи с помощью стека FileBeat, Kafka, ElasticSearch и выводим через Kibana. Такой подход позволяет каждому разработчику просматривать логи в удобном формате.
Планы на будущее
Учи.ру растет, соответственно, мы будем обучать сотрудников и расширять штат, чтобы усилить команду. Постоянное повышение качества платформы остается в нашем приоритете, а также автоматизация процессов там, где сейчас требуется ручное вмешательство инженера.
Еще одно стратегически важное направление работы — покрытие инфраструктуры более детальным мониторингом, например, в следующем году мы планируем использовать Elastic application performance monitoring, чтобы быстрее находить узкие или проблемные места.
Для нас важно, чтобы разработчики могли без помощи администраторов настраивать и хостить приложения. Поэтому мы развиваем и продолжим развивать инфраструктуру как платформу-сервис для внутренних потребностей компании.
Задача, напрямую не связанная с ИТ-инфраструктурой, при этом не менее важная — это развитие инженерной культуры у членов команды и в компании в целом.
Поделиться
 Короткая ссылка
Короткая ссылка





